Platform Engineering and DevOps
A Mental Model for Platform Engineering and DevOps
A co-worker recently asked me when is the right moment to build a platform when building a software organization what made me thinking about the exact term and when to actually start taking care nurtoring a platform in a software organization. This post is an attempt to bring certain aspects I know and have read about for multiple years into the equation and provide a holistic view on DevOps and Platform Engineering.
The DevOps Hype and Delusion, and Science
Depending on different sources, the DevOps movement really ignited in 2009 at the Velocity Conference when John Allspaw and Paul Hammond demonstrated how Flickr deployed to production ten times a day, a number that seemed almost like Science Fiction for the audience1.
After that the usual hype cycle set in while the unicorns and FAANG companies started making their mark in the industry and pushing the needle further in regards to velocity metrics (Amazon deploying to production every 11.6 seconds in 20232)
Unfortunately, those results were hard to replicate for a broader population mainly because there was no recipe fo success that was based on empiristic evidence or research on how to achieve the promises of DevOps as a organization.
2012, Puppet started conducting the State of DevOps survey to draw a conclusive picture on the adoption of DevOps principles and outcomes3. That effort was later taken over by the DevOps Research and Assessment (Dora), a research organization funded mainly by Google.
Based on this data, in 2018 Dr. Nicole Forsgren, Jez Humble and Gene Kim published the book Accelerate, which scientifically proved the positive effects on organizations and individuals alike when implementing DevOps principles. Additionally, it established four metrics to describe Software Delivery Performance and score System Performance in general4 now commonly referred as DORA metrics.
- Lead Time
- Deployment Frequency
- Mean Time to Restore
- Change Fail Percentage
While additional analysis also found evidence that good Software Delivery Performance correlates with good organizational culture and individual well-being5, correlation and causation have not been fully understood at that point.
In addition to that, Goodhart's law started diminishing the effectiveness of the metrics almost immediately after publication as practitioners and managers alike started pushing for higher rankings on those metrics without improving both technological capabilities and organizational culture leading to mixed results.
Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure"6.
Turning Correlation into Causation
As research went on both on Microsoft Developer Experience Lab, DORA and other places, the term of Developer Experience and Productivity came up to describe a set of technical capabilities and organizational measures that enables good Software Delivery performance.
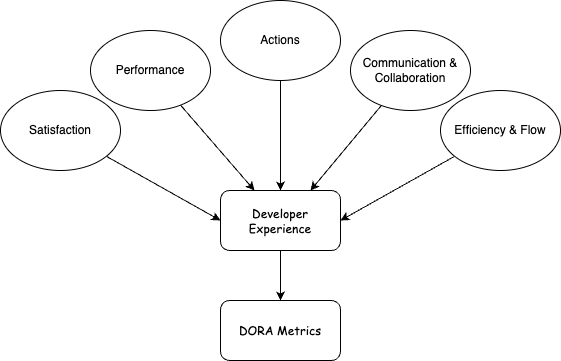
Most prominently is the SPACE Framework published in 20217 that focuses on five dimensions to better understand Developer Experience. As Software Engineering is a socio-technical exercise, metrics are qualitative (survey data) and quantitative (system metrics).
- Satisfaction and well-being
- Performance
- Action
- Communication and collaboration
- Efficiency and flow
To improve the DORA metrics for an organization, it is necessary to invest into metrics from different dimensions as these are causally interconnected according to the paper. Additional research has been conducted and recently published8 as well deepening the focus on the individual developers experience whereas DORA indicates solely system performance.
Technical Capabilities and Platform
Recently, DevOps practitioners shifted into two diverging directions:
- Site Reliability Engineering
- Platform Engineering
While the first one is already well-understood and established both within the industry9 as well within the literature10, the latter is still in Hype phase and not well-defined yet.
Starting with the Platform term, let's use the following working definition:
The platform is the sum of technological capabilities and systems used to develop and deliver software.
This includes, but is not limited to the following elements:
- CI/CD
- GitOps
- Source Control
- Automated Testing
- Infrastructure as Code
- Container and Container Orchestration
- Security and Compliance Measures
In separation of SRE, where the lifecycle of a singular service is the scope, Platform Engineering aims to provide a common platform for all teams involved in developing and delivering software across the organization.
Note: Deploying Kubernetes and integrating all CNCF projects is not necessarily Platform Engineering. Deploying a Backstage.io is not, either.
Designing, operating, and managing of the platform itself is where the engineering part of the term comes into play.
The "Golden Path" and Product Market Fit
The ultimate goal of platform teams is 100% adoption of the platform by the software teams across the organization. As this is illusional for a lot of reasons11, platform teams are craving for it talking about "paving a golden path".
This golden path is meant to make it easy and worthwhile for application teams to integrate into the common platform and abandon duplicates of functions and capabilities that are provided by the platform team (like contesting CI/CD systems, orchestrators, ...).
NOTE: Platform Engineering is not about forcing seniors into a particular IDE, but providing juniors and new joiners with a workspace that allows them to contribute quickly, confidently and safely.
Providing the technical capabilities ("product") required by the application teams ("the market) is what platform engineering is all about.
So finding "market fit" for the platform is actually an exercise in Product Engineering12.
What to work on next?
In essence, there is never a green-field deployment for a "platform" because even in a fresh start-up the first software engineer will walk in and open her favorite IDE and create the first pipeline in her CI/CD system of choice, which is then the platform that will be iterated upon. Therefore, it is unreasonable to think of platform engineering with a fixed starting point or to ask "When to start building a platform?"
Alternatively, platform engineers should be thinking about the most lacking SPACE metrics and provide technical capabilities that can potentially lift up those values. As this is based on hypotheses and experiments, the correct way of working would follow a Deming Cycle of Plan - Do - Check - Act.
One example would be the following: survey data of software engineers indicates discontent with inconsistencies when executing pipelines. Analysis shows that software versions vary greatly between different CI runners. In this scenario, the next best thing to work on the platform would be to improve the CI system by using build containers with a fixed tag on all runners to harmonize the environment. After applying the change, both the quantitative metrics of number of successfuly pipeline runs should be increasing as well and the qualitative measure of perceived flow for the engineers.
Conclusion
By integrating DORA metrics, the SPACE Framework as well as all technical capabilities constituting the platform, the following Bow-Tie model can be used to illustrate a platform engineering team's mission.
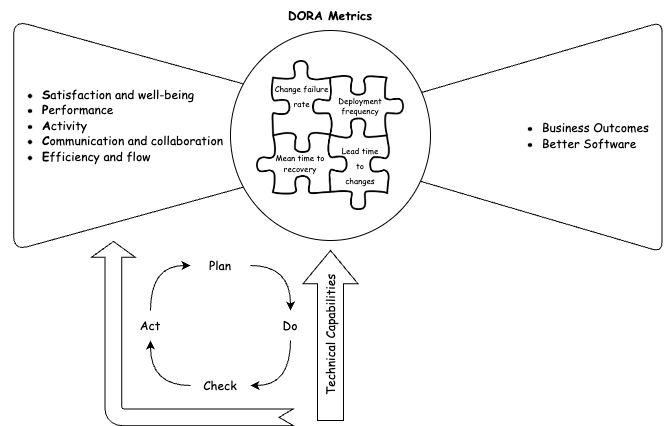
As described SPACE metrics are predicting software delivery performance operationalized using the DORA metrics which result in better business outcomes and higher-quality software. Technical capabilities developed by the platform engineering team have effects both on SPACE metrics as well as on the DORA metrics.
To decide on how to improve your platform, you would need to identify lacking metrics on the right side, form a hypothesis on what capability could provide an uptick on this particular metric, implement a solution and test the hypothesis.
By applying this mental model as a platform team, platform teams can focus on improving developer experience in a measurable fashion without getting trapped too deep into the usual hype surrounding new terms and practices within our industry.
Sources
Kim, G., Humble, J., Debois, P., Willis, J., & Forsgren, N. (2016). The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (1st ed.). IT Revolution. (p. 5)↩
Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: The science of lean software and DevOps: Building and scaling high performing technology organizations. IT Revolution Press. (p. 17)↩
Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: The science of lean software and DevOps: Building and scaling high performing technology organizations. IT Revolution Press. (p. 88)↩
Forsgren, N., Wernick, C., Kamerer, T., Redmiles, E. M., & Herbsleb, J. (2020). The SPACE of Developer Productivity: There’s more to it than you think. Proceedings of the ACM on Human-Computer Interaction, 4(CSCW2), 1–35. https://doi.org/10.1145/3432934↩
Noda, A., Storey, M.-A., Forsgren, N., & Greiler, M. (2023). DevEx: A Practical Framework for Measuring and Improving Developer Experience. Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 1–14. https://doi.org/10.1145/3411763.3451612↩
Limoncelli, T. A., Chalup, S. R., & Hogan, C. J. (2014). The practice of cloud system administration: DevOps and SRE practices for web services. Pearson Education. (p. 401)↩
Kim, G., Humble, J., Debois, P., Willis, J., & Forsgren, N. (2016). The DevOps handbook: How to create world-class agility, reliability, and security in technology organizations. IT Revolution. (p. 297).↩
Platform engineering is just DevOps with a product mindset - StackOverflow Blog↩